
新智元报道
编辑:好困
【新智元导读】国际顶会历来是AI技术的试金石,也是各家企业大秀肌肉的主战场。
近日,第31届ACM信息与知识管理国际会议(The 31th ACM International Conference on Information and Knowledge Management,CIKM 2022)公布录用结果,度小满AI Lab的三篇文章被录用。
ExpertBert: Pretraining Expert Finding
Efficient Non-sampling Expert Finding
Deep View-Temporal Interaction Network for News Recommendation
CIKM创办于1992年,是全球信息检索和数据挖掘领域的顶级学术会议之一,享有较高的学术声誉。度小满已多次在CIKM、ACM MM、CVPR等国际顶会发表论文,其AI前沿技术能力已堪比国际一线机构。
这次被录用的三篇论文,分别在预训练模型、用户表示、序列建模等NLP任务相关算法上取得突破性进展。
其中,用于专家发现任务的ExpertBert模型,弥合了预训练目标与下游建模任务的差距,能够精准识别潜在的信贷需求;ENEF模型,基于非采样策略进行专家发现,增强了问题和用户表示的鲁棒性和稳定性,成为CQA领域兼具性能与效率的最优方法;DeepVT模型,全面有效地捕捉和融合视图和时序模式,使小微客群的行为预测更精准。
度小满AI Lab负责人杨青表示,这些算法与金融行业的用户行为预测高度相关,对于风险评估,信贷获客和老客经营等信贷业务至关重要。目前以上创新技术已在实际业务上落地应用。
以下是三篇论文内容速览:
ExpertBert:用户粒度预训练框架,快速匹配高质量回答
论文题目:ExpertBert: Pretraining Expert Finding
如何将专业问题推荐给专家或感兴趣的用户,是知乎、StackOverflow等社区问答(CQA)网站运营的关键。类似地,这项「专家发现」任务在金融信贷获客业务中,同样发挥着重要作用。
根据该业务需求,NLP算法能够通过对用户行为序列数据的有效预训练,精准识别出用户潜在的信贷需求,降低信贷获客成本,提高用信率。
从现有研究来看,预训练语言模型(PLM,如BERT)因强大的文本建模能力,在「用户画像」等建模任务中表现良好。
然而,这些预训练模型大多基于语料或者文档粒度,与下游用户粒度建模任务并不一致。这表明,现有PLM模型并不能完全建模专家与问题的匹配模式,专家发现需要设计一种更有效的预训练框架。
度小满团队提出的专家发现预训练语言模型ExpertBert,在预训练阶段有效地在统一了文本表示、用户建模和下游任务,能够使预训练目标更接近下游任务,在CQA用户表示方面做出了开创性贡献。
杨青介绍说,用户级别的预训练模型ExpertBert,进一步增强了原始语料库级的预训练方法,通过掩码语言模型,提高了问题与相关专家之间的匹配度。在信贷业务中,能够帮助平台更精准获客,更有效地触达潜在客群。
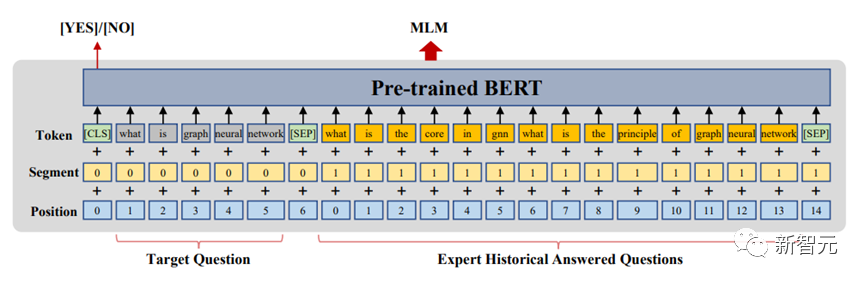
ExpertBert框架图
据悉,ExpertBert是第一个在CQA领域探索专家发现预训练语言模型的方法,且在真实数据集上证明了模型的有效性和性能的优越性。目前,该方法已在度小满信贷获客场景中开展使用,其头部用信人数的召回相对提升了超10%。
ENEF:高性能、低计算复杂度的「非采样」专家发现模型
论文题目:Efficient Non-sampling Expert Finding
高度数据化的金融业,是人工智能和云计算等数据驱动技术的最好应用场景之一。在信贷业务中,AI算法除了可用于精准获客外,亦可服务于用户流失预警业务。
「我们通过征信/互金等外部数据源,建立用户-信贷产品多行为交互矩阵,使用非采样技术能够利用全部样本数据,动态预测用户的潜在的流失风险和潜在的留存行为。相比以往的方法,非采样模型在结清、流失客群等场景的应用,大幅提升了有效召回人数」,杨青说。
据悉,非采样的算法的关键是从整个训练数据中学习用户特征,不需要对数据进行负采样。
同样在专家发现领域,大多数方法基于负采样策略进行效率训练,但这种方法往往是不稳健的。因为负采样对不同的采样方法和数量高度敏感,会使预训练结果出现有偏和鲁棒性差的问题。而且,负采样也可能损失大量用户的有用信息,导致训练不足和次优性能。
但如果不进行采样,基于整个数据的训练则可能导致计算复杂度和资源过高。
为了解决这一问题,推荐领域提出了一些相对成熟的「非采样」策略。但这些方法仅关注单用户交互数据的点击率场景,在CQA领域并不适用。相比推荐领域,CQA的专家发现任务更具有挑战性:
一是冷启动问题:CQA中的问题是实时发布的,ID嵌入不可用,需要从标题中推断问题语义信息。二是「问题-专家」关系匹配的复杂度更高。比如对于特定问题,每个回答会因为专家水平分为不同的类型。基于这两点,要想在专家发现中直接应用非采样并非易事。
高效非采样专家发现框架ENEF,采用基础的问题编码器,能够从标题中捕捉问题的语义特征,并且通过精心设计的高效全数据优化方法,在不进行负采样的情况下学习模型参数,解决了非抽样范式普遍存在的高计算复杂度的难题。
此外,基于这些策略,ENEF可以从所有数据样本中更新模型参数,增强问题和专家表示的稳健性和准确性。
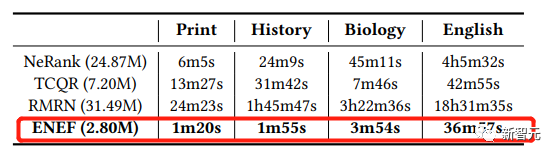
值得注意的是,与大多数复杂神经网络方法相比,ENEF使用基础框架和少量参数,达到了更高的训练效率。经对比实验验证,是当前CQA非抽样专家发现模型中,性能最好且训练效率更高的最优方法。
DeepVT:视图与时序模式交互,全面、精准预测用户画像
论文题目:Deep View-Temporal Interaction Network for News Recommendation
在金融行业,如何有效地捕捉小微等不同客群的用户风格特点,准确学习用户的复杂行为表示是金融风控、获客、经营、反欺诈等应用场景的核心挑战。如今随着经济形势日渐复杂,用户的行为与风险愈加难以预测,而相关算法的「短板」也愈加显现。
度小满AI Lab团队表示,「用户历史行为的建模在信贷AB卡、金科小满分等模型中是非常重要的一环。之前的工作大多只将项目级表示直接应用于用户建模中,视图级的信息往往被压缩,这使得不同浏览项目中的不同视图无法有效的融合」。
所以,DeepVT模型主要关注于用户建模的视图级信息,有效解决了用户画像建模中仅关单一的视图交互或时序信息的问题。该模型构建了2D半因果卷积神经网络(SC-CNN)和多算子注意力(MoA)两个模块。其中,前者可以同时高效地合成视图级别的交互信息和项目级别的时间信息;而后者在自注意力函数中综合不同的相似算子,可以避免注意力偏差,增强鲁棒性。
经过在真实数据的实验与严谨的理论证明,DeepVT在所有指标方面都显著优于传统模型,且能够有效地建模复杂的用户访问行为信息,挖掘各类用户特征,提升相应风控模型的性能。
写在后面
作为人工智能领域的金融科技企业,度小满坚持技术创新,布局前沿技术领域,已在深度学习、自然语言语言处理、图神经网络、情感计算等重点研发方向上积累了丰富的经验和成果。
此前,度小满的神经网络结构搜索(NAS)论文入选国际顶会CVPR Workshop;自然语言处理技术在微软MARCO比赛中超越三星、微软、谷歌、斯坦福斩获第一;自创TranS模型在知识图谱「世界杯」OGB挑战赛中斩获榜首;多模态与排序等论文被ACM MM、CIKM等国际顶会接收。其相关技术成果颇受学术界、业界认可,并已被广泛应用。




















