
新智元报道
编辑:LRS
【新智元导读】GitHub上榜项目靠谱,拿来就能用!
看完一篇AI论文,要是发现代码没公开,心就得凉半截,瞬间对实验结果都要开始怀疑。

最近有网友收集了八月份发表的10642篇AI论文,发现其中90.9%的论文都没有公开代码。
在公开的一千份代码中,根据其在GitHub上收获Stars数量做了一个排行榜,排名前二的论文都是语言-图像模型相关的研究。

文末还有在推特上排行前十的AI研究列表,部分只有论文,没有代码。
1. 用一个词描述一张图
Text-to-image模型通过自然语言来指导创作图像,提供了前所未有的自由度。
但目前还不清楚如何利用这种自由来生成指定的、具有独特概念的图像,或者修改图像的外观,或将它们组成新的角色和新的场景。
可以用一个简单的问题来描述:我们如何利用language-guided模型把「自己的」猫变成一幅画,或者在「自己最喜欢的」玩具的基础上想象出一个新产品?
来自特拉维夫大学和英伟达的研究人员提出了一个简单的方法,只需使用3-5张用户提供的图片,比如一个物体或一种风格,无需微调text-to-image模型,即可在通过新的word在embedding空间中学习表示用户输入。

论文链接:https://arxiv.org/abs/2208.01618
项目链接:https://textual-inversion.github.io/
代码链接:https://github.com/rinongal/textual_inversion
这些word可以作为自然语言句子中的一部分,以更直观的方式来指导个性化的创作。

比如输入一些用户图片,即可生成一个特殊的word来表示该风格或物体。

甚至还可以在自然语言句子中组合多个新words

值得注意的是,研究人员发现有证据表明,单个词的embedding足以捕捉到独特且多样的概念。
在将该方法与大量的基线模型进行比较后,可以证明它能更忠实地描绘一系列应用和任务中的概念。
2. 从语言-图像到视频
经过对比学习训练的「图像文本模型」在从整个「互联网规模」的数据中学习visual-textual联合表征方面取得了巨大成功,并在各种图像任务中表现出超强的zero-shot泛化能力。
但我们该如何将这种新的language-image预训练方法有效地扩展到视频领域?目前仍然是一个开放的问题。
来自微软研究院、中国科学院、石溪大学和罗切斯特大学的研究人员提出了一个简单而有效的方法,可以将预训练的language-image方法直接用于视频识别,而不必从头开始预训练一个新的模型。

论文链接:https://arxiv.org/abs/2208.02816
代码链接:https://github.com/microsoft/videox
具体来说,为了捕捉视频帧在时间维度上的长距离依赖性,文中提出了一个跨帧注意力(cross-frame attention)机制,显式地交换不同帧之间的信息。
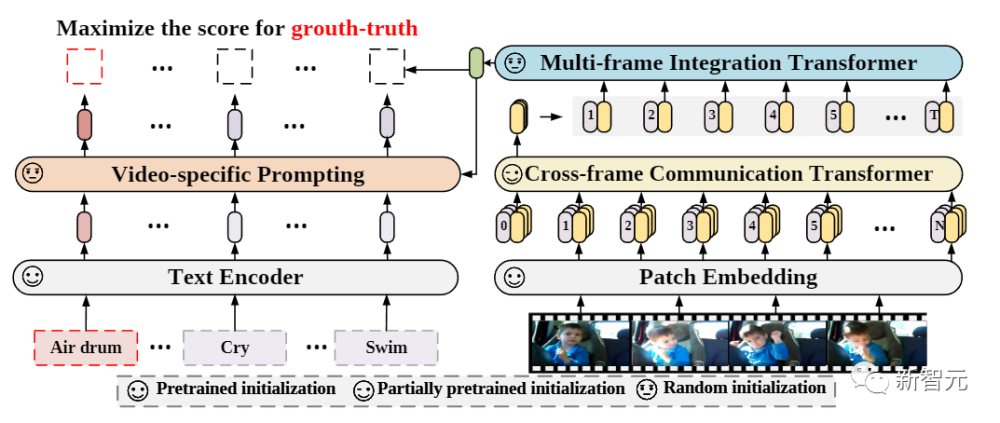
这样设计得到的模块是轻量级的,可以可以无缝地插入到预训练的语言-图像模型中。
此外,研究人员还提出了 一个针对视频的prompt模式,能够利用视频的内容信息来生成有辨识度的文本提示。
经过大量的实验后,可以证明该方法是有效的,并且能够被推广到 不同的视频识别场景。
在完全监督(fully-supervised)的情况下,该方法在Kinectics-400上达到了87.1%的top-1准确率,并且FLOPs仅为Swin-L和ViViT-H的十二分之一。

在zero-shot实验中,在两个常用的协议下,该方法以+7.6%和+14.9%的最高准确率超过了目前的sota方法。
在few-shot实验中,当标签数据极其有限时,该方法比以前的最佳方法高出+32.1%和+23.1%
3. 无需噪声的扩散模型
目前业界出现的扩散(Diffusion)模型变体层出不穷,但「随机噪声」是不变的核心。
标准的扩散模型包括图像变换(image transform),添加高斯噪声,和一个反转图像退化的恢复算子。
来自马里兰大学和纽约大学的研究人员观察到,扩散模型的生成行为并不依赖于图像退化的选择,事实上,通过改变这种选择,可以构建整个生成模型系列。

论文链接:https://arxiv.org/abs/2208.09392
代码链接:https://github.com/arpitbansal297/cold-diffusion-models
即使在使用完全确定的退化(如模糊、遮蔽等)时,作为扩散模型基础的训练和测试时间更新规则也可以很容易地被泛化以创建生成模型。
这些完全确定的模型的成功使人们对社区对扩散模型的理解产生了疑问,这种理解依赖于梯度朗文动力学(gradient Langevin dynamics)或变分推理中的噪声,并为反转任意过程的泛化扩散模型铺平了道路。

在这篇论文中,作者不再将扩散模型局限于「依赖高斯噪声而建立」,而是提出了围绕模糊(blurring)、下采样(downsampling)等任意图像变换方式建立的广义扩散模型。
由于不再有原先的「高温」状态,这种全新广义扩散模型也就被称作为 Cold Diffusion。
4. 让大模型走进消费级GPU
大型语言模型目前已成为主流NLP研究的基础,但使用大模型需要大量的GPU内存进行推理。

论文链接:https://arxiv.org/abs/2208.07339
代码链接:https://github.com/timdettmers/bitsandbytes
来自华盛顿大学、Meta AI研究院、Hugging Face的研究人员为Transformer中的前馈和注意力投影层开发了一个Int8矩阵乘法的程序,使得推理所需的内存减少了一半,同时还能保持全精度的性能。
使用该方法,可以很方便地加载一个175B参数的16/32位checkpoint,转换为Int8后,也不会出现性能下降的情况。

想要做到这一点,需要通过理解和绕过Transformer语言模型中高度系统化的突发特征的特性来进行实现,这些特征主导着注意力和Transformer的预测性能。
为了应对这些特征,研究人员开发了一个由两部分组成的量化(quantization)程序:LLM.int8()。首先使用矢量量化,对矩阵乘法中的每个内积都使用单独的归一化常数,以量化大多数特征。
对于出现的异常值,文中还提出一个新的混合精度分解方案,该方案将异常值特征维度隔离到16位的矩阵乘法中,与此同时仍有超过99.9%的值是以8位乘法的。
根据经验表明,使用LLM.int8()可以在参数高达175B的LLM中进行推理而不会有任何性能下降。
该项目也使得这种大模型的使用场景更广泛,例如,有可能在装有消费级GPU的单一服务器上使用OPT-175B/BLOOM
5. 联邦学习本地蒸馏
来自慕尼黑工业大学的研究人员提出了一个全新的联邦学习(federated learning)框架FedD3,减少了整体的通信量,大大扩展了联邦学习的应用场景,即使是在网络受限的环境中也能使用。

论文链接:https://arxiv.org/abs/2208.11311
代码链接:https://github.com/Guang000/Awesome-Dataset-Distillation
相比传统的学习方法,FedD3通过本地数据集的蒸馏实现了(1)显著减少通信量;(2)限制了transfer到one-shot的通信量,而非迭代的多路(multi-way)通信;

和其他联邦学习方法中共享模型更新不同的是,FedD3让连接的客户端独立蒸馏本地数据集,然后将这些分散的、蒸馏后的数据集(以一些无法识别的图像的形式存储,正常来说比一个模型小)在整个网络上汇总一次,以形成最终的模型。
实验结果表明,FedD3在所需的通信量方面明显优于其他的联邦学习框架,同时它还能够在准确性和通信成本之间的进行平衡,具体取决于使用场景和目标数据集。
例如,要是想用10个客户端在Non-IID CIFAR-10上训练AlexNet模型,与其他one-shot联邦学习方法相比,在通讯量不变的情况下,FedD3可以将准确率提高71%以上;如果准确率相同,则可以节省98%的通信量。
6. 隐式表征数据集
神经辐射场(NeRFs)在隐三维表征(implicit 3D representation)方面取得了诸多进展,可以用一种可微分的方式进行准确且逼真的三维重建。
这种新的表征方法可以在一个紧凑的格式中有效地传达数百个高分辨率图像的信息,并允许对新的视图进行逼真的合成。
来自浦项科技大学、英伟达和加州理工大学的研究人员利用NeRF的变种Plenoxels,创建了第一个用于感知任务的大规模隐式表征数据集PeRFception

论文链接:https://arxiv.org/abs/2208.11537
代码链接:https://github.com/POSTECH-CVLab/PeRFception
数据集由两部分组成,包括以物体为中心和以场景为中心的扫描,可以用于分类和分割。
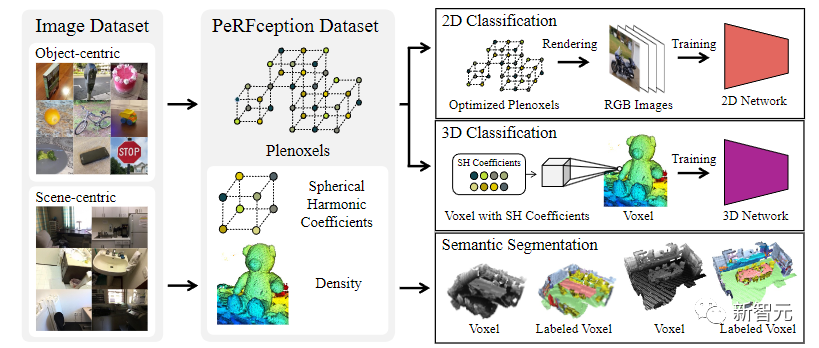
在原始数据集的基础上实现了显著的内存压缩率(96.4%),同时以统一的形式包含了二维和三维信息。
研究人员直接将这种隐式格式作为输入构建了分类和分割模型,还提出了一种新的增强技术,可以避免对图像背景的过拟合。
7. 最小的视频实例分割框架
研究人员提出了MinVIS,一个最小的视频实例分割(VIS)框架,在既没有基于视频的架构也没有训练程序的情况下,实现了最先进的VIS性能。

论文链接:https://arxiv.org/abs/2208.02245
代码链接:https://github.com/nvlabs/minvis
通过只训练一个基于查询的图像实例分割模型,MinVIS在比较难的Occluded VIS数据集上的表现比以前的最佳结果要好10%以上。
由于MinVIS将训练视频中的帧视为独立的图像,因此可以在不做任何修改的情况下对训练视频中的标注帧进行大幅度的子采样。

在YouTube-VIS 2019/2021上,MinVIS只用了1%的标注帧,就超过了完全监督的最先进的方法,或者与之相当。
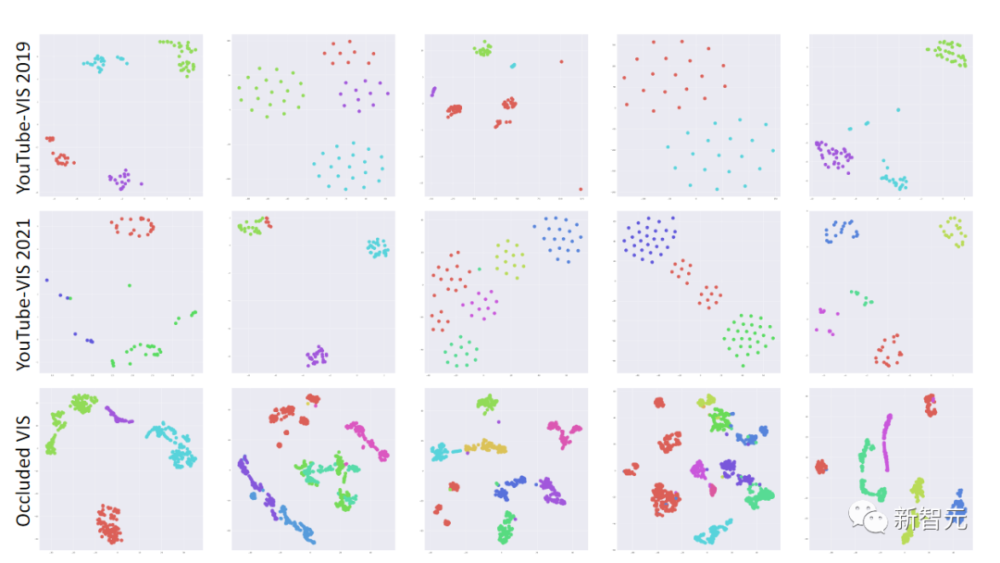
主要观察结果是,经过训练的查询在帧内物体实例之间具有判别能力,在时间上是一致的,可以用来追踪实例,而不需要任何人工设计的启发式方法。
因此,MinVIS的推理pipeline为:先将训练好的基于查询的图像实例分割独立应用于视频帧,然后通过对相应的查询进行双边匹配来追踪被分割的实例。

这种推理是以在线方式进行的,不需要一次性处理整个视频。所以MinVIS具有降低标签成本和内存需求的实际优势,同时不会牺牲VIS的性能。
8. 用来唱歌的Vocoder
Vocoder是一种条件音频生成模型,将声学特征(如旋律谱图)转换成波形。
从可微分数字信号处理(DDSP)中得到启发,研究人员提出了一种新的Vocoder,名为SawSing,可以用于歌唱的声音。

论文链接:https://arxiv.org/abs/2208.04756
代码链接:https://github.com/yatingmusic/ddsp-singing-vocoders
SawSing通过用线性时变有限脉冲响应滤波器过滤锯齿源信号来合成歌声的谐波部分,该滤波器的系数是通过神经网络从输入的旋律谱图中估计出来的。
由于这种方法加强了相位的连续性,SawSing可以产生歌唱的声音,而不会出现许多现有vocoder的相位不连续的突变。

此外,源滤波器的假设提供了一个感应性的偏向,使SawSing可以在少量的数据上进行训练。
实验表明,在资源有限的情况下,SawSing收敛得更快,并优于最先进的生成式对抗网络和基于扩散的vocoder,只有3个训练记录和3小时的训练时间。
9. 无需模型的强化学习
深度强化学习是在不需要领域知识的不可控环境中学习策略的一种有效的方法。
不幸的是,由于样本的低效率,深度强化学习的应用主要集中在模拟环境中。
在这项工作中,研究人员证明了机器学习算法和库的最新进展与精心调整的机器人控制器相结合,在现实世界中只需20分钟就能学会四足动物的运动。

论文链接:https://arxiv.org/abs/2208.07860
代码链接:https://github.com/ikostrikov/walk_in_the_park
研究人员在几个室内和室外的地形上评估了该方法,这些地形对于经典的基于模型的控制器来说是具有挑战性的,观察到机器人能够在所有这些地形上持续学习行走步态,文中也在一个模拟环境中评估了该设计决策。

10. 物联网攻击检测
现代车辆,包括自动驾驶车辆和联网车辆,通过与其他车辆、智能设备和基础设施的连接和通信,逐渐包含了越来越多的功能。
但车联网(IoV)日益增长的连接性也增加了对网络攻击的脆弱性。
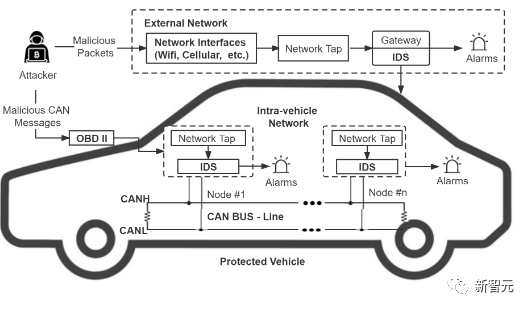
为了保护物联网系统免受网络威胁,有研究使用机器学习(ML)方法开发了能够识别恶意网络攻击的入侵检测系统(IDS)。
为了准确地检测物联网网络中的各种类型的攻击,研究人员提出了一个全新的集成IDS框架,取名为为领导者类和信心决策集成(Leader Class and Confidence Decision Ensemble, LCCDE)。

论文链接:https://arxiv.org/abs/2208.03399
代码链接:https://github.com/Western-OC2-Lab/Intrusion-Detection-System-Using-Machine-Learning
通过在三种最先进的ML算法(XGBoost、LightGBM和CatBoost)中为每一类或每一种攻击类型确定表现最好的ML模型。
然后利用具有预测置信度值的类领袖模型,对各种类型的网络攻击的检测做出准确的决定。
在两个公共物联网安全数据集(Car-Hacking和CICIDS2017数据集)上的实验证明了所提出的LCCDE对车辆内部和外部网络的入侵检测的有效性。
推特排名前十的研究

参考资料:
https://www.reddit.com/r/MachineLearning/comments/x4vppv/d_most_popular_ai_research_aug_2022_ranked_based/



















